|
I am a Senior Research Scientist at Google DeepMind, working on Gemini models! I earned my Ph.D. from Language Technologies Institute (LTI) at School of Computer Science, Carnegie Mellon University, where I was advised by Emma Strubell. Before that I obtained a Master's degree (2019) from the LTI where I was advised by Jaime Carbonell and Barnabás Póczos. Before joining CMU, I worked as a member of the research staff at Big Data Research Lab, Adobe Research (2015-17) where I worked on designing algorithms for identifying data-driven geo-fences to assist Adobe’s digital marketing offering. I graduated from Indian Institute of Technology Roorkee with a B.Tech in Computer Science (2011-15) and a President's Gold Medal. Email / CV / Google Scholar / X |

|
|
My current research focuses on developing advanced training paradigms for LLMs, leveraging mid-training optimization, continual/lifelong learning, and reinforcement learning for enhanced efficiency, adaptation, and scaling. My doctoral thesis focused on designing efficient lifelong learning systems to overcome catastrophic forgetting and enable continual learning of new tasks. Inspired by biological learning and deep learning advances, this thesis involved injecting inductive biases into core machine learning components: model (architecture & initialization), training (objective & optimization), and data (leveraging limited labeled & unlabeled data). |
|
|
|
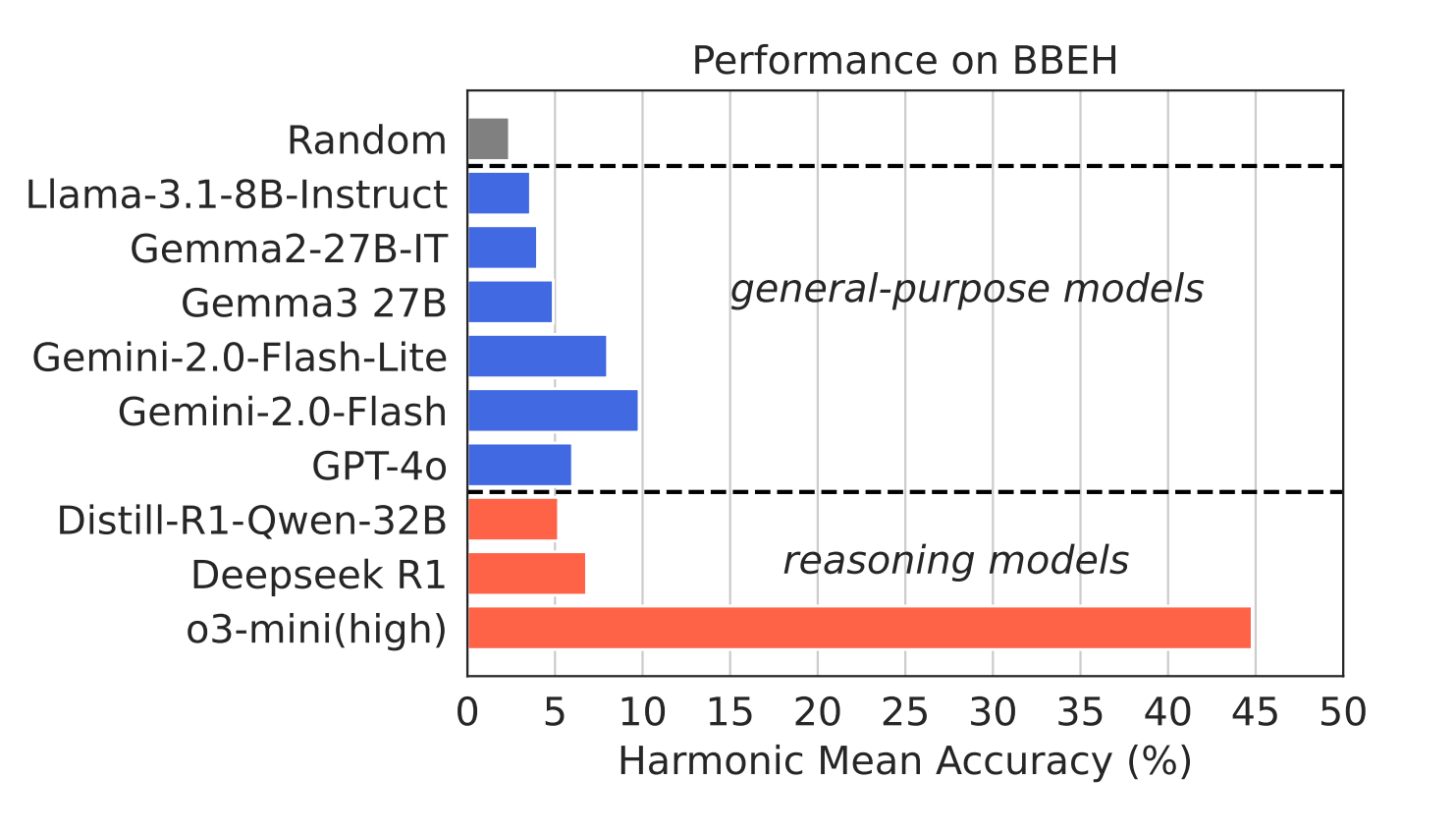 |
Mehran Kazemi, Bahare Fatemi, Hritik Bansal, John Palowitch, Chrysovalantis Anastasiou, Sanket Vaibhav Mehta, Lalit K. Jain, Virginia Aglietti, Disha Jindal, Peter Chen, Nishanth Dikkala, Gladys Tyen, Xin Liu, Uri Shalit, Silvia Chiappa, Kate Olszewska, Yi Tay, Vinh Q. Tran, Quoc V. Le, Orhan Firat ACL, 2025 bibtex / code / tweet |
 |
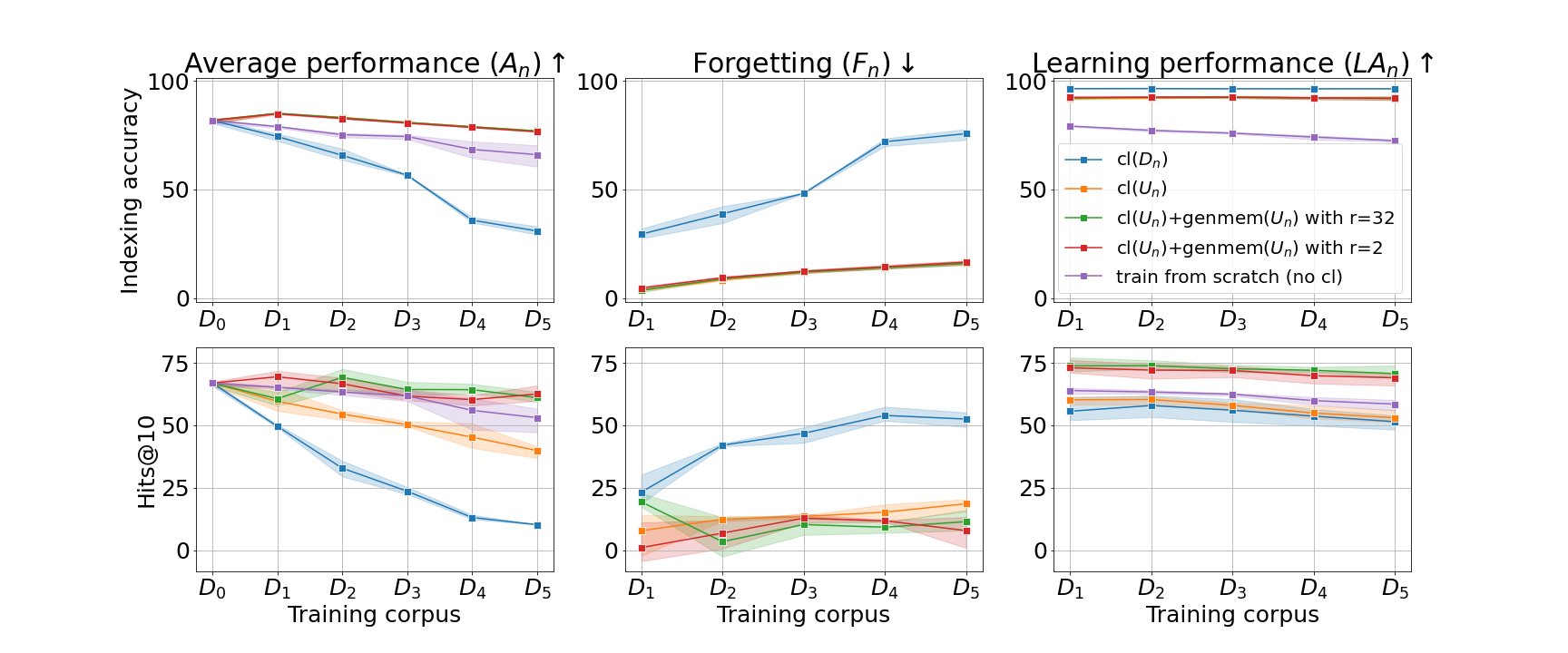
Sanket Vaibhav Mehta PhD Thesis, Carnegie Mellon University, 2023 bibtex / tweet |
 |
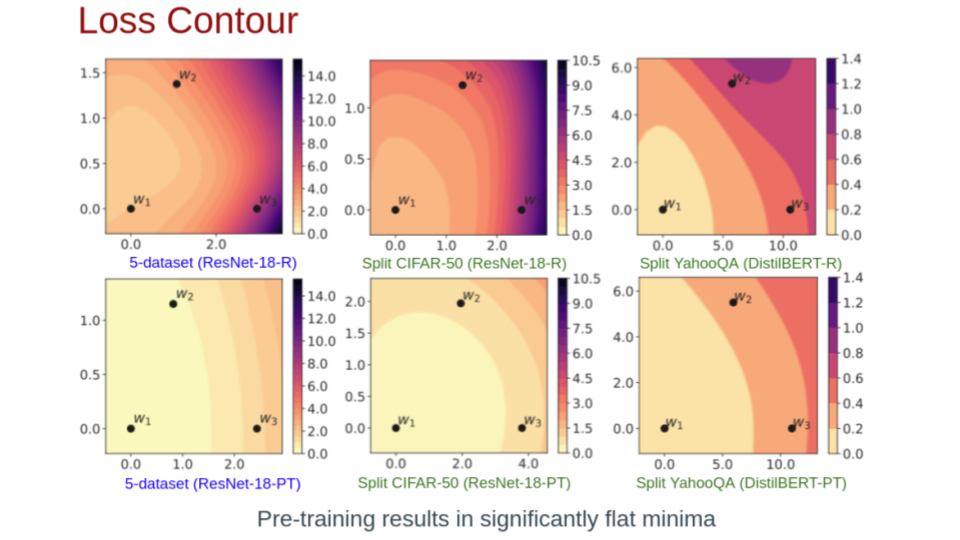
Sanket Vaibhav Mehta, Jai Gupta, Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Jinfeng Rao, Marc Najork, Emma Strubell, Donald Metzler EMNLP, 2023 bibtex / tweet |
 |
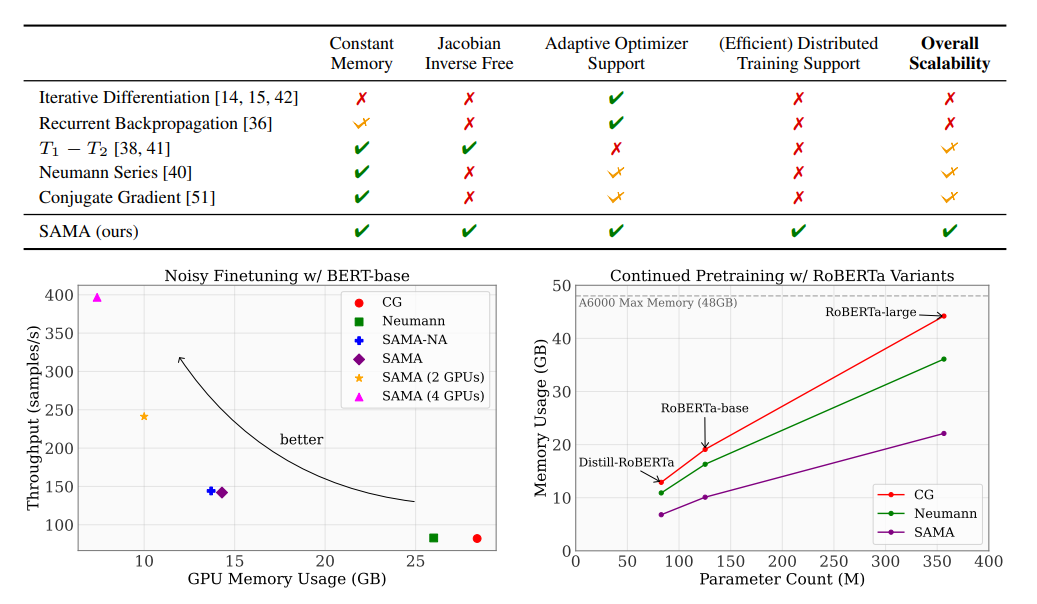
Sanket Vaibhav Mehta, Darshan Patil, Sarath Chandar, Emma Strubell Journal of Machine Learning Research, 2023 bibtex / code / tweet |
 |
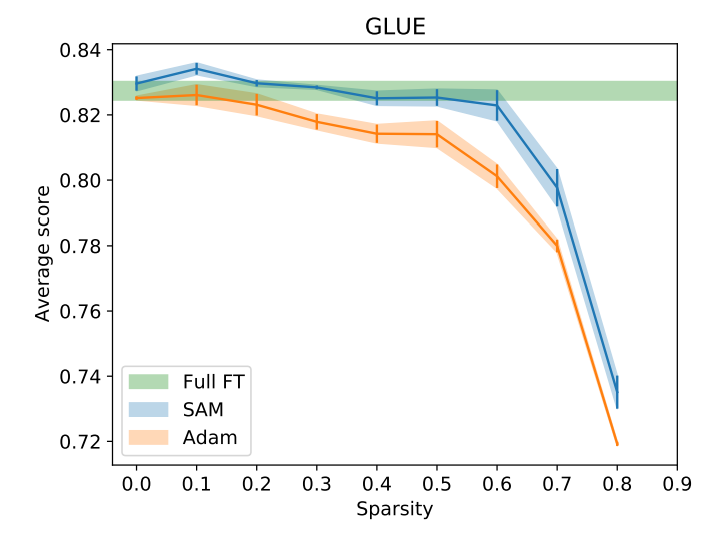
Sang Keun Choe, Sanket Vaibhav Mehta, Hwijeen Ahn, Willie Neiswanger, Pengtao Xie, Emma Strubell, Eric Xing NeurIPS, 2023 bibtex / code / tweet |
 |
Clara Na, Sanket Vaibhav Mehta, Emma Strubell EMNLP Findings, 2022 bibtex / code / tweet |
 |
Shagun Sodhani, Mojtaba Faramarzi, Sanket Vaibhav Mehta, Pranshu Malviya, Mohamed Abdelsalam, Janarthanan Janarthanan, Sarath Chandar arXiv, 2022 bibtex / tweet |
 |
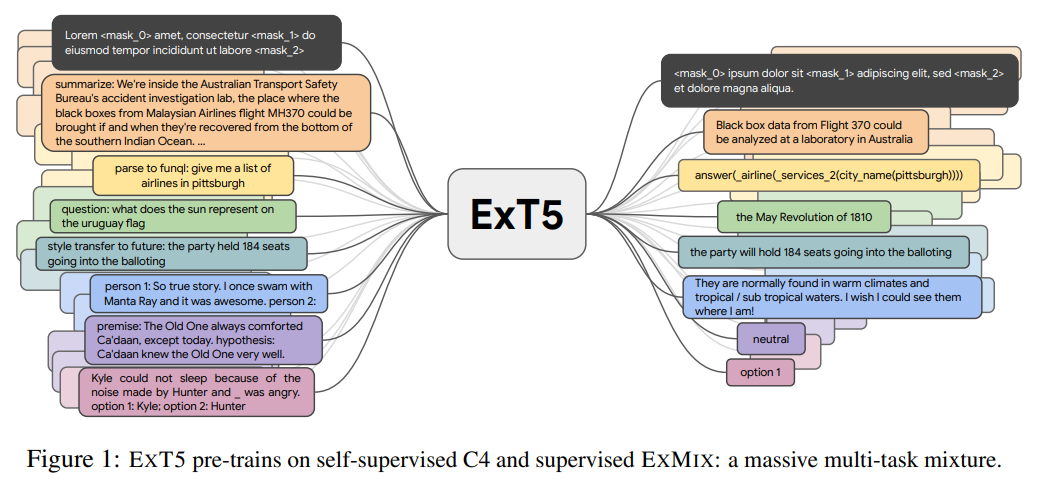
Sanket Vaibhav Mehta, Jinfeng Rao, Yi Tay, Mihir Kale, Ankur Parikh, Emma Strubell ACL, 2022 bibtex / code / poster |
 |
Vamsi Aribandi, Yi Tay, Tal Schuster, Jinfeng Rao, Huaixiu Steven Zheng, Sanket Vaibhav Mehta, Honglei Zhuang, Vinh Q. Tran, Dara Bahri, Jianmo Ni, Jai Gupta, Kai Hui, Sebastian Ruder, Donald Metzler ICLR, 2022 bibtex / press / tweet |
|
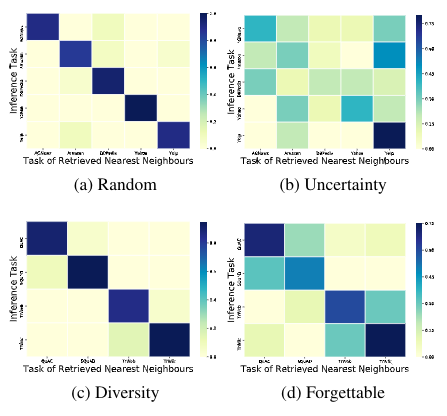
Sanket Vaibhav Mehta, Darshan Patil, Sarath Chandar, Emma Strubell ICML Theory and Foundation of Continual Learning Workshop, 2021 (Spotlight) bibtex / code |
 |
Sanket Vaibhav Mehta*, Zirui Wang*, Barnabás Póczos, Jaime Carbonell EMNLP, 2020 bibtex |
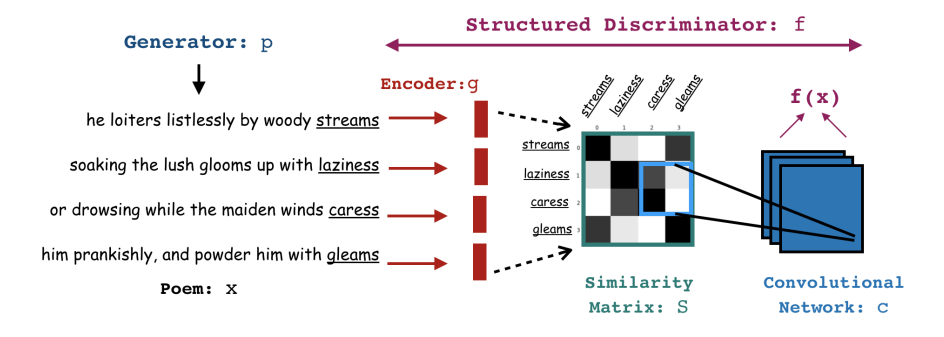 |
Harsh Jhamtani, Sanket Vaibhav Mehta, Jaime Carbonell, Taylor Berg-Kirkpatrick EMNLP, 2019 bibtex / code / poster |
 |
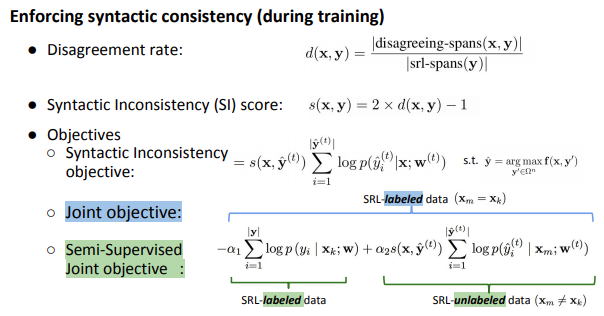
Jay-Yoon Lee, Sanket Vaibhav Mehta, Michael Wick, Jean-Baptiste Tristan, Jaime Carbonell AAAI, 2019 bibtex / code |
 |
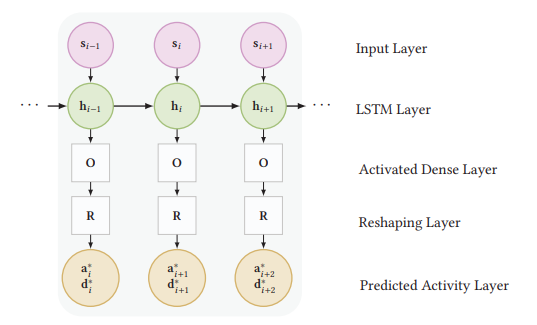
Sanket Vaibhav Mehta*, Jay-Yoon Lee*, Jaime Carbonell EMNLP, 2018 bibtex / code / poster |
 |
Kundan Krishna, Deepali Jain, Sanket Vaibhav Mehta, Sunav Choudhary IMWUT, 2017 bibtex |
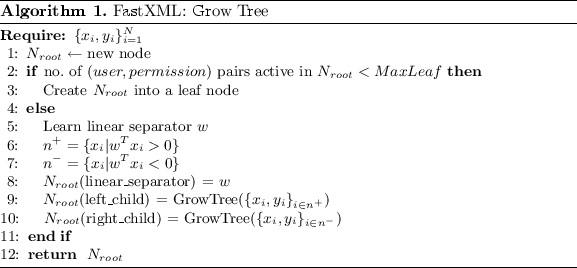 |
Tanya Goyal, Sanket Vaibhav Mehta, Balaji Vasan Srinivasan PAKDD, 2017 bibtex |
Based on Jon Barron's website.